<Interacting with Databases>
1. Interacting with a (remote) database
Backend developers need to interact with databases on a regular basis in order to manipulate and maintain the models behind their web applications. In this lesson, we'll build a foundational understanding of how those interactions work.
This foundational understanding will be essential in later lessons when we get into more advanced concepts related to database interactions.
In working with a database, we'll need to use a Database Management System (DBMS).
A Database Management System (DBMS) is simply software that allows you to interact with a database (e.g., to access or modify the data in that database).
There are many different Database Management Systems out there, but the particular DBMS we'll be using is called PostgreSQL (or simply Postgres).
2. Database Application Programming Interfaces (DBAPIs)
Once we've looked at the basics of interacting with a database, we'll need to understand how to interact with that database from another language or web server framework (such as Python, NodeJS, Ruby on Rails, etc.). This is where DBAPIs come in.
In this lesson, we'll go over the basics of DBAPIs, and how they are used to interact with a database from another language (like Python).
3. psycopg2
Finally, we'll get some experience working with the widely used psycopg2 library, which will allow us to interact with a database from Python.
psycopg2 is a database adapter that allows us to interact with a Postgres database from Python.
<Relational Databases>
Over the next couple of pages, we'll briefly go over some of the fundamental concepts concerning relational databases. In general, we're assuming that you've had some experience with relational databases, and that these ideas are not entirely new to you.
If this is new to you, or if you feel shaky on this topic, don't worry—we'll provide some additional resources that you can use to learn (or review) the basics that you'll need for this course.
Resources
If you'd like to spend some time going over the basic concepts of relational databases, you can check out Udacity's free course Intro to Relational Databases.
I also recommend this video, An Introduction to Relational Databases, which introduces the thinking behind relational databases, how they resolve issues of inconsistent data entry, and how they allow different pieces of data to relate to one another using primary keys (we'll talk more about primary keys in a moment).
<Primary Keys & Foreign Keys>
Takeaways
Primary Key
- The primary key is the unique identifier for the entire row, referring to one or more columns.
- If there are more multiple columns for the primary key, then the set of primary key columns is known as a composite key.
Foreign Key
- A primary key in another (foreign) table.
- Foreign keys are used to map relationships between tables.
<SQL>
Manipulating Data
Querying Data
Structuring Data
Joins & Groupings
<Execution Plan>
Let's check out the execution plan!
In SQLFiddle, you'll notice a link that says "View Execution Plan" after running a SQL command (see the green bar near the bottom).
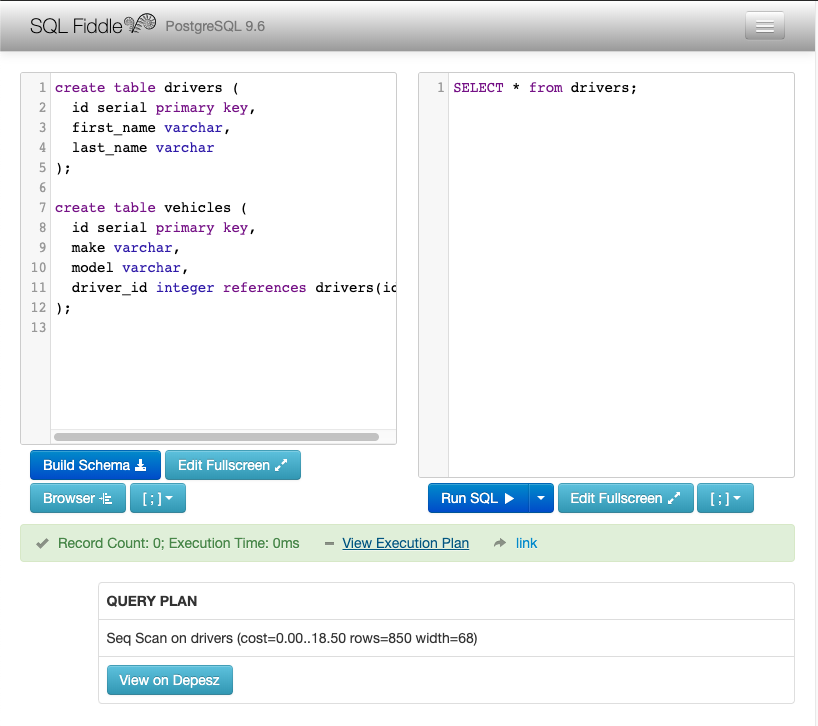
View the execution plan and generally be familiar with what is happening to the database under the hood. The execution plan gives important insight into the performance of the query. Since there can multiple ways of performing queries against a database with various performance tradeoffs, it's important to choose the one with the best execution plan for quickly and efficiently returning the results that you need.
In SQLFiddle, for a particular result, click on the "View Execution Plan" link, and under Query Plan, click on "View on Depesz".
For a SELECT * operation, the most basic operation is Seq Scan ("Sequential Scan"), as explained here on depesz.com, where PostgreSQL opens the file storing the table, then reads each rows, one by one, returning them to user. We should generally know that this is what happens when we do a SELECT statement.
Let's look at something more complicated. For running a join,
SELECT make, model from vehicles JOIN drivers on vehicles.driver_id = drivers.id;
The execution plan looks like this:
- Hash Join: joins two record sets. It is the most expensive part of the plan, as indicated by the 'cost', it is joining every row! (Is that necessary? Can we accomplish finding out what we need while devising an execution plan that doesn't require this?) The hash join creates a hash in-memory that hashes based the driver_id column.
- Seq Scan: a sequential scan is done across the entire vehicles table. This makes sense since we're looking to fetch all make and model information across all records in the vehicles table.
- Hash with Seq Scan on drivers: as the sequential scan continues, the join key is checked in the Hash returned from Step 1, where if it does NOT exist, given that this is an Inner Join, we ignore that row, and if it does exist (a record was found that does intersect between the vehicles and drivers tables), then we fetch the row from the hash to generate the outputted, joined row.
We can always gain visibility over how performant a given SQL query is by looking at its execution plan.
On Performance
Learning how to write efficient queries is practically its own field. There are techniques for improving the performance of SQL queries to consider, we can use critical indexes to speed up information lookups, and there are helpful utilities like SQL views for splitting queries into subroutines.
It won't be necessary to understand how to optimize SQL queries to complete the rest of this course. However, you may want to look particularly into SQL Indexes and generally have a performance-oriented mindset with regards to writing efficient queries. I recommended reading and following the blog, Use the Index, Luke! as a highly in-depth guide to database performance for developers.
How important is it to know about the performance of your SQL queries? Well, would you want to visit a site that takes 4 seconds to load your results (every time you do a search), or a half of a second? You tell me...
Knowing and applying performance strategies to a SQL query can wound up being really powerful.
{kind=link}
Now for some fun resources on Hashes:
- What is a HashTable Data Structure video explanation by Paul Programming
- Intro to Hash tables
<Client-Server Model>
In order to build database-backed web applications, we first need to understand how servers, clients, and databases interact.
A major part of this is the client-server model, so let's look at that first. The basic idea is very simple, and looks something like this:

A server is a centralized program that communicates over a network (such as the Internet) to serve clients.
And a client is a program (like the web browser on your computer) that can request data from a server.
When you go to a web page in your browser, your browser (the client) makes a request to the server—which then returns the data for that page.
Adding databases to the model
So that's the basic client-server model. But when you add in databases, this creates a little more complexity.
In this next video, we'll review the basic model and then see how databases fit into things.
In summary, relational database systems follow a client-server model:
Servers, Clients, Hosts
- In a Client-Server Model, a server serves many clients.
- Servers and clients are programs that run on hosts.
- Hosts are computers connected over a network (like the internet!).
Requests and Responses
- A client sends a request to the server
- The server's job is to fulfill the request with a response it sends back to the client.
- Requests and responses are served via a communication protocol, which sets up the expectations and rules for how the communication occurs between servers and clients.
Relational Database Clients
- A database client is any program that sends requests to a database
- In some cases, the database client is a web server! When your browser makes a request, the web server acts as a server (fulfilling that request), but when the web server requests data from the database, it is acting as a client to that database—and the database is the server (because it is fulfilling the request).
Don't let this confuse you. Basically, we call things clients when they are making a request and servers when they are fulfilling a request. Since a web server can do both, it sometimes acts as a server and sometimes acts as a client.
<Client-Server Model Example: Jane's Store>
Client-Server Model Example: Jane's Store
In this next series of videos, we'll walk through how client-server interactions would occur in an example of an online store. We'll see how traffic gets routed from a web client, to a web server, to a database, and eventually back to a web client.
Takeaways
- Clicking on the Polo product leads to a click event being registered by the browser, on the client computer.
- A click handler in the view would send a request to the server (in Javascript) from the client browser.
- A client could request more data and a different view to be rendered (with that data).
- A server process listens to the request sent from the view. It fetches the data and chooses what to render next, using the fetched data.
Takeaways
- The client sends a request to the server, including information about the request type and any user input data.
- The server receives the request, and uses the user input data to determine how to shape its request to the database, and sends a request to the database.
- The database processes this request, and sends a response back to the web server.
- The server receives the response from the database, and uses it to determine the view + powers the view template with the fetched data, sending it back to the client's browser.
- The client is responsible for rendering something to the user, that represents both the data and its representation.
<TCP/IP>
In this section, we'll look at the suite of communication protocols that is used to transfer data over the Internet. These communication protocols are most often referred to as TCP/IP, which is an abbreviation that refers to the two main protocols involved—Transmission Control Protocol (TCP) and Internet Protocol (IP).
Takeaways
TCP/IP is a suite of communication protocols that is used to connect devices and transfer data over the Internet.
TCP/IP uses:
- IP addresses: An IP address identifies the location of a computer on a network.
- Ports: A port is a location on the recipient computer, where data is received.
While an IP address tells you where to find a particular computer, it doesn't tell you specifically where on that computer a particular connection should be made—that's what port numbers are for.
Some port numbers you should know:
- Port 80: The port number most commonly used for HTTP requests. For example, when a client makes a request to a web server, this request is usually sent through port 80.
- Port 5432: The port number used by most database systems; default port for Postgres.
<Connections and Sessions in TCP/IP>
Takeaways
- TCP/IP is connection-based, meaning all communications between parties are arranged over a connection. A connection is established before any data transmission begins.
- Over TCP/IP, we'll always need to establish a connection between clients and servers in order to enable communications. Moreover:
- Deliveries over the connection are error-checked: if packets arrive damaged or lost, then they are resent (known as retransmission).
- Connecting starts a session. Ending the connection ends the session.
- In a database session, many transactions can occur during a given session. Each transaction does work to commit changes to the database (updating, inserting, or deleting records).
Aside: the UDP Protocol
The internet also offers the UDP protocol. UDP stands for User Datagram Protocol. UDP is much simpler than TCP: hosts on the network send data (in units called datagrams) without any connections needing to be established.
TCP vs UDP
If TCP is like building highways between houses before sending packages between them, then UDP is much like sending over a carrier pigeon from one house to another in order to deliver packages: you don't know whether the pigeon will head in the right way, drop your package along the way, or encounter an issue mid-travel. On the other hand, there is less overhead to use UDP than managing a connection over TCP / building a highway.
When speed is more important than reliability, especially when applications need to stream very small amounts of information quickly (smaller packages of information means less issues with reliability), then UDP is preferred. A lot of real time streaming applications, (e.g. live TV streaming, Voice over IP (VoIP)) prefer UDP over TCP. Since UDP does not need to retransmit lost datagrams, nor does it do any connection setup, there are fewer delays over UDP than TCP. TCP's continuous connection is more reliable but has more latency.
<Transactions>
Takeaways
- Databases are interacted using client-server interactions, over a network
- Postgres uses TCP/IP to be interacted with, which is connection-based
- We interact with databases like Postgres during sessions
- Sessions have transactions that commit work to the database
Transactions capture logical bundles of work.
Work is bundled into transactions, so that in case of system failures, data in your database is still kept in a valid state (by rolling back the entire transaction if any part of it fails). To ensure a database is consistent before and after work is done to it, databases uses atomic transactions, and actions like commits and rollbacks to handle failures appropriately. Transactions are, in other words, ACID.
Resource on ACID Properties
See: ACID Properties in DBMS on GeeksforGeeks.org
<Installing Postgres>
Install Postgres
Before we can use Postgres, we'll need to install it. You may already have Postgres, for example if you're a MacOS user, it already comes installed on your machine. But just in case, here are some steps for downloading and installing it.
Go to the Postgres Download page and download Postgres for your machine.
- For MacOS, Postgres is already downloaded. Homebrew is a popular route for installing Postgres. See this gist on installing Postgres via Brew.
- On Linux, you can run apt-get install postgresql
- For Windows, download the installer from PostgreSQL Database Download page. The installer will install PostgreSQL server and pgAdmin, a GUI for managing Postgres databases.
You should know that you successfully installed Postgres if you can run the following in your terminal, and see a path outputted:
$ which postgres /usr/local/bin/postgres
Next: Start a Postgres server on your local machine
For MacOS Users:
From the Postgres.app, it's as simply as hitting the "Initialize" button. Follow the instructions on the Postgres.app homepage to configure and initialize a postgres server.
From the command line:
On MacOS, to stop an already initialized postgres server
$ pg_ctl -D /usr/local/var/postgres stop
to start a postgres server
$ pg_ctl -D /usr/local/var/postgres start
See How to start, stop, and restart a postgresql server to follow steps for your particular operating system.
Initial installation settings
The initial installation will:
- create an initial database named postgres
- create an initial user named postgres. Your postgres user will have no password set by default.
- create initial databases called template1 and template0. Any other database created after template1 is a clone of template1, including its tables and rows. If you add rows (objects) to template1, they will be copied onto future created databases. template0, on the other hand, should stay "pure" and never be changed.
- The default host machine that runs your postgres server, on your machine, is localhost (aka, 127.0.0.1)
- The default port traditionally used to host your server is port 5432. There are very few reasons to use a different port than 5432.
Default connection settings are:
FieldDefault Value
| Host | localhost |
| Port | 5432 |
| Username | postgres |
| Password | (left blank) |
Additional References:
- Template DatabasesLet's deep dive into what Postgres is
- Postgres is an open source, general purpose and object-relational database management system, considered by many to be the most advanced open source database system available. It's a relational database system extended with object-oriented features, that works across operating systems.
- Object-relational support includes support for arrays (multiple valuesin a single column), and inheritance (child-parent relationships between tables).
- Built since 1977, it is lauded for being highly stable, requiring minimal effort to maintain compared to other systems.
- Widely used, everywhere: by Apple, Cisco, Etsy, Microsoft, Yahoo, Reddit, Instagram, Uber,... and many others.
- Comprehensive support for the SQL standard.
- Transaction-based: operations on the database are done through atomic transactions.
- Has multi-version concurrency control, avoiding unnecessary locking when multiple writes are happening to the database at once (avoiding waiting times for access to the database)
- Postgres lets you have several databases available for reading from and writing to, at once.
- Offers great performance and many indexing capabilities for optimizing query performance
- PostgreSQL is also often just called Postgres, and we'll be using both terms interchangeably throughout this course.
- Postgres is an open source, general purpose and object-relational database management system, considered by many to be the most advanced open source database system available. It's a relational database system extended with object-oriented features, that works across operating systems.
<Postgres Command Line Applications>
Postgres CLI tools
Keep this as a general reference. You'll be using these commands quite a lot if you are building web apps with Postgres.
Log in as a particular user
Default installed user is called postgres
sudo -u <username> -i
e.g. sudo -u bob -i
Create a new database
createdb <database_name>
e.g. createdb mydb
Destroy a database
dropdb <database_name>
e.g. dropdb mydb
Reset a database
dropdb <database_name> && createdb <database_name>
e.g. dropdb mydb && createdb mydb
Try it yourself!
Gain technical proficiency in managing postgres databases by practicing creating, dropping, and resetting databases. Do this in your terminal, if you successfully installed Postgres on your local computer, or interact with the terminal in this workspace below, which already has Postgres installed.
<Intro to psql>
Postgres CLI tools
Keep this as a general reference. You'll be using these commands quite a lot if you are building web apps with Postgres.
Log in as a particular user
Default installed user is called postgres
sudo -u <username> -i
e.g. sudo -u bob -i
Create a new database
createdb <database_name>
e.g. createdb mydb
Destroy a database
dropdb <database_name>
e.g. dropdb mydb
Reset a database
dropdb <database_name> && createdb <database_name>
e.g. dropdb mydb && createdb mydb
Try it yourself!
Gain technical proficiency in managing postgres databases by practicing creating, dropping, and resetting databases. Do this in your terminal, if you successfully installed Postgres on your local computer, or interact with the terminal in this workspace below, which already has Postgres installed.
<Other Postgres Clients>
So, do you need to use psql to do web development?
No. Other popular client alternatives for inspecting and interacting with your postgres server are:
The course videos will heavily rely on using psql.
Part 2: database adapters, default connection settings
Takeaways
Generally know the default connection settings that come with your Postgres installation. You'll need to set them for every connection you make (on pgAdmin, PopSQL, your web server, etc).
Connection SettingDefault
| Host | localhost (aka, 127.0.0.1) |
| Port | 5432 |
| Username | postgres |
| Password | (None) |
<DBAPIs and psycopg2>
Takeaways
We will sometimes want to interact with our database and use its results in a specific programming language. E.g. to build web applications or data pipelines in a specific language (Ruby, Python, Javascript, etc.). That's where DBAPIs come in.
- A DBAPI
- provides a standard interface for one programming language (like Python) to talk to a relational database server.
- Is a low level library for writing SQL statements that connect to a database
- is also known as database adapters
- Different DBAPIs exist for every server framework or language + database system
- Database adapters define a standard for using a database (with SQL) and using the results of database queries as input data in the given language.
- Turn a selected SELECT * from some_table; list of rows into an array of objects in Javascript for say a NodeJS adapter; or a list of tuples in Python for a Python adapter.
Examples across languages and server frameworks
- For Ruby (e.g. for Sinatra, Ruby on Rails): pg
- For NodeJS: node-postgres
- For Python (e.g. for Flask, Django): pyscopg2
psycopg2 is the focus of this course since we are using a Python stack.
Install psycopg2
We will install pysocpg2 and use it to establish a connection to our postgres server, and interact with it in python.
psycopg2 installation steps
Follow the psycopg2 install instructions found here.
Install Tips:
- Make sure you have Python 3 version between 3.4 to 3.7. You can find out with$ python --version
- Use the latest pip version: $ pip3 install -U pip
- Replace X.Y in the export PATH... line with the version of Postgres you are using. Find out with $ postgres -V. E.g.:$ postgres -V postgres (PostgreSQL) 10.2If the version is 10.2, then replace the X.Y in the export PATH line with 10.2:export PATH=/usr/lib/postgresql/10.2/bin/:$PATH
- In ~/.bash_profile or ~/.bashrc, we should add:
- To export and add things to your PATH, add the export PATH=.... line to either ~/.bashrc or ~/.bash_profile on your machine, e.g. with vim:$ vim ~/.bashrc` # or $ vim ~/.bash_profilewhere you can use :w, :wq vim commands to edit your bash file and add the export PATH=... line somewhere. (See also: Vim tutorial
- When you are done editing your bash profile, be sure to run source ~./bash_profile or source ~/.bashrc on your edited file, so your terminal session can grab the latest profile changes.
- After editing your bash profile, you are ready to run the install step:$ pip install pyscopg2
- A prerequisite for psycopg2 is OpenSSL. If you try installing and run into error ld: library not found for -lssl, then install openssl first.
- On homebrew (for macOS or Linux): run brew install openssl (or sudo brew install openssl)
- Otherwise, you can visit the OpenSSL Downloads page to download OpenSSL for your machine.
- Add the LIBRARY_PATH to your bash profile:export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/opt/openssl/lib/Don't forget to run source ~/.bash_profile or source ~/.profile when done.
- If the regular install doesn't work, you can also just install the binary version instead:pip install psycopg2-binarywhich replaces the need to run pip install pyscopg2
- Install troubleshooting threads:
- For error Failed building wheel for psycopg2: https://stackoverflow.com/questions/34304833/failed-building-wheel-for-psycopg2-macosx-using-virtualenv-and-pip
- For error pg_config executable not found: https://stackoverflow.com/questions/11618898/pg-config-executable-not-found
'[Udacity] Full Stack Web Developer' 카테고리의 다른 글
| [Introduction to SQL and Data Modeling for the Web] Course Overview (0) | 2021.10.30 |
|---|