<Databases>
Rule 1: The information rule:
All information in a relational database is represented explicitly at the logical level and in exactly one way – by values in tables.
More information on Codd's 12 Rules can be found here:
<Importance of Relational Databases>
Importance of Relational Databases:
- Standardization of data model: Once your data is transformed into the rows and columns format, your data is standardized and you can query it with SQL
- Flexibility in adding and altering tables: Relational databases gives you flexibility to add tables, alter tables, add and remove data.
- Data Integrity: Data Integrity is the backbone of using a relational database.
- Structured Query Language (SQL): A standard language can be used to access the data with a predefined language.
- Simplicity : Data is systematically stored and modeled in tabular format.
- Intuitive Organization: The spreadsheet format is intuitive but intuitive to data modeling in relational databases.
<OLAP vs OLTP>
Online Analytical Processing (OLAP):
Databases optimized for these workloads allow for complex analytical and ad hoc queries, including aggregations. These type of databases are optimized for reads.
Online Transactional Processing (OLTP):
Databases optimized for these workloads allow for less complex queries in large volume. The types of queries for these databases are read, insert, update, and delete.
The key to remember the difference between OLAP and OLTP is analytics (A) vs transactions (T). If you want to get the price of a shoe then you are using OLTP (this has very little or no aggregations). If you want to know the total stock of shoes a particular store sold, then this requires using OLAP (since this will require aggregations).
Additional Resource on the difference between OLTP and OLAP:
This Stackoverflow post describes it well.
<Objectives of Normal Form>
Objectives of Normal Form:
- To free the database from unwanted insertions, updates, & deletion dependencies
- To reduce the need for refactoring the database as new types of data are introduced
- To make the relational model more informative to users
- To make the database neutral to the query statistics
See this Wikipedia page to learn more.
<Normal Forms>
- How to reach First Normal Form (1NF):
- Atomic values: each cell contains unique and single values
- Be able to add data without altering tables
- Separate different relations into different tables
- Keep relationships between tables together with foreign keys
- Second Normal Form (2NF):
- Have reached 1NF
- All columns in the table must rely on the Primary Key
- Third Normal Form (3NF):
- Must be in 2nd Normal Form
- No transitive dependencies
- Remember, transitive dependencies you are trying to maintain is that to get from A-> C, you want to avoid going through B.
- When you want to update data, we want to be able to do in just 1 place. We want to avoid updating the table in the Customers Detail table (in the example in the lecture slide).
- What is the maximum normal form that should be attempted while doing practical data modeling?
Third normal form
<Denormalization>
Denormalization:
JOINS on the database allow for outstanding flexibility but are extremely slow. If you are dealing with heavy reads on your database, you may want to think about denormalizing your tables. You get your data into normalized form, and then you proceed with denormalization. So, denormalization comes after normalization.
Citation for slides: https://en.wikipedia.org/wiki/Denormalization
- Denormalization does NOT just allow data to come in as it is with no organization or planning. It is a part of the data modeling process to make data more easily queried.
<Denormalization vs Normalization>
Let's take a moment to make sure you understand what was in the demo regarding denormalized vs. normalized data. These are important concepts, so make sure to spend some time reflecting on these.
Normalization is about trying to increase data integrity by reducing the number of copies of the data. Data that needs to be added or updated will be done in as few places as possible.
Denormalization is trying to increase performance by reducing the number of joins between tables (as joins can be slow). Data integrity will take a bit of a potential hit, as there will be more copies of the data (to reduce JOINS).
Example of Denormalized Data:
As you saw in the earlier demo, this denormalized table contains a column with the Artist name that includes duplicated rows, and another column with a list of songs.

Example of Normalized Data:
Now for normalized data, Amanda used 3NF. You see a few changes:
1) No row contains a list of items. For e.g., the list of song has been replaced with each song having its own row in the Song table.
2) Transitive dependencies have been removed. For e.g., album ID is the PRIMARY KEY for the album year in Album Table. Similarly, each of the other tables have a unique primary key that can identify the other values in the table (e.g., song id and song name within Song table).
Song_Table
Album_Table
Artist_Table
<Fact and Dimension Tables>
Citations for slides:
- https://en.wikipedia.org/wiki/Dimension_(data_warehouse)
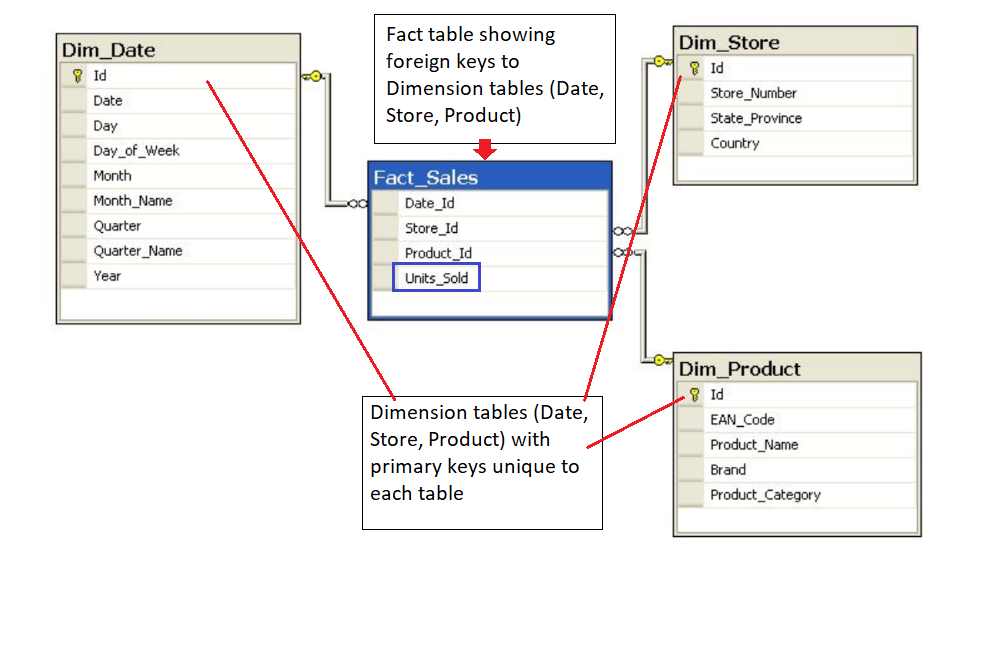
- https://en.wikipedia.org/wiki/Fact_tableThe following image shows the relationship between the fact and dimension tables for the example shown in the video. As you can see in the image, the unique primary key for each Dimension table is included in the Fact table.
The Fact table provides the metric of the business process (here Sales).
- Where the product was bought? (Dim_Store table)
- When the product was bought? (Dim_Date table)
- What product was bought? (Dim_Product table)
- How many units of products were bought? (Fact_Sales table)
- In this example, it helps to think about the Dimension tables providing the following information:
- If you are familiar with Entity Relationship Diagrams (ERD), you will find the depiction of STAR and SNOWFLAKE schemas in the demo familiar. The ERDs show the data model in a concise way that is also easy to interpret. ERDs can be used for any data model, and are not confined to STAR or SNOWFLAKE schemas. Commonly available tools can be used to generate ERDs. However, more important than creating an ERD is to learn more about the data through conversations with the data team so as a data engineer you have a strong understanding of the data you are working with.
- More information about ER diagrams can be found at this Wikipedia page
<Star Schemas>
Star schema - Wikipedia
In computing, the star schema is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts.[1] The star schema consists of one or more fact tables referencing any number of dimension t
en.wikipedia.org
<Benefits of Star Schemas>
- Benefits:
Denormalized
Simplifies queries
Fast aggregations
- Drawbacks:
Issues that come with denormalization
Data integrity
Decrease query flexibility
Many-to-many relationship
<Snowflake Schemas>
Snowflake schema - Wikipedia
The snowflake schema is a variation of the star schema, featuring normalization of dimension tables. In computing, a snowflake schema is a logical arrangement of tables in a multidimensional database such that the entity relationship diagram resembles a sn
en.wikipedia.org
This Medium post provides a nice comparison, and examples, of Star and Snowflake Schemas. Make sure to scroll down halfway through the page.
Deep Diving in the World of Data Warehousing
“Information is the oil of the 21st century, and analytics is the combustion engine”. — Peter Sondergaard, Senior Vice President, Gartner.
bluepi-in.medium.com
<Data Definition and Constraints>
Data Definition and Constraints
The CREATE statement in SQL has a few important constraints that are highlighted below.
NOT NULL
The NOT NULL constraint indicates that the column cannot contain a null value.
Here is the syntax for adding a NOT NULL constraint to the CREATE statement:
CREATE TABLE IF NOT EXISTS customer_transactions ( customer_id int NOT NULL, store_id int, spent numeric );
You can add NOT NULL constraints to more than one column. Usually this occurs when you have a COMPOSITE KEY, which will be discussed further below.
Here is the syntax for it:
CREATE TABLE IF NOT EXISTS customer_transactions ( customer_id int NOT NULL, store_id int NOT NULL, spent numeric );
UNIQUE
The UNIQUE constraint is used to specify that the data across all the rows in one column are unique within the table. The UNIQUE constraint can also be used for multiple columns, so that the combination of the values across those columns will be unique within the table. In this latter case, the values within 1 column do not need to be unique.
Let's look at an example.
CREATE TABLE IF NOT EXISTS customer_transactions ( customer_id int NOT NULL UNIQUE, store_id int NOT NULL UNIQUE, spent numeric );
Another way to write a UNIQUE constraint is to add a table constraint using commas to separate the columns.
CREATE TABLE IF NOT EXISTS customer_transactions ( customer_id int NOT NULL, store_id int NOT NULL, spent numeric, UNIQUE (customer_id, store_id, spent) );
PRIMARY KEY
The PRIMARY KEY constraint is defined on a single column, and every table should contain a primary key. The values in this column uniquely identify the rows in the table. If a group of columns are defined as a primary key, they are called a composite key. That means the combination of values in these columns will uniquely identify the rows in the table. By default, the PRIMARY KEY constraint has the unique and not null constraint built into it.
Let's look at the following example:
CREATE TABLE IF NOT EXISTS store ( store_id int PRIMARY KEY, store_location_city text, store_location_state text );
Here is an example for a group of columns serving as composite key.
CREATE TABLE IF NOT EXISTS customer_transactions ( customer_id int, store_id int, spent numeric, PRIMARY KEY (customer_id, store_id) );
To read more about these constraints, check out the PostgreSQL documentation.
<Upsert>
Upsert
In RDBMS language, the term upsert refers to the idea of inserting a new row in an existing table, or updating the row if it already exists in the table. The action of updating or inserting has been described as "upsert".
The way this is handled in PostgreSQL is by using the INSERT statement in combination with the ON CONFLICT clause.
INSERT
The INSERT statement adds in new rows within the table. The values associated with specific target columns can be added in any order.
Let's look at a simple example. We will use a customer address table as an example, which is defined with the following CREATE statement:
CREATE TABLE IF NOT EXISTS customer_address ( customer_id int PRIMARY KEY, customer_street varchar NOT NULL, customer_city text NOT NULL, customer_state text NOT NULL );
Let's try to insert data into it by adding a new row:
INSERT into customer_address ( VALUES (432, '758 Main Street', 'Chicago', 'IL' );
Now let's assume that the customer moved and we need to update the customer's address. However we do not want to add a new customer id. In other words, if there is any conflict on the customer_id, we do not want that to change.
This would be a good candidate for using the ON CONFLICT DO NOTHING clause.
INSERT INTO customer_address (customer_id, customer_street, customer_city, customer_state) VALUES ( 432, '923 Knox Street', 'Albany', 'NY' ) ON CONFLICT (customer_id) DO NOTHING;
Now, let's imagine we want to add more details in the existing address for an existing customer. This would be a good candidate for using the ON CONFLICT DO UPDATE clause.
INSERT INTO customer_address (customer_id, customer_street) VALUES ( 432, '923 Knox Street, Suite 1' ) ON CONFLICT (customer_id) DO UPDATE SET customer_street = EXCLUDED.customer_street;
We recommend checking out these two links to learn other ways to insert data into the tables.
<Conclusion>
What we learned:
- What makes a database a relational database and Codd’s 12 rules of relational database design
- The difference between different types of workloads for databases OLAP and OLTP
- The process of database normalization and the normal forms.
- Denormalization and when it should be used.
- Fact vs dimension tables as a concept and how to apply that to our data modeling
- How the star and snowflake schemas use the concepts of fact and dimension tables to make getting value out of the data easier.
'[Udacity] Data Engineer' 카테고리의 다른 글
| Lesson 1: Introduction to Data Modeling (0) | 2021.09.22 |
|---|---|
| [Introduction to Data Engineering] Roles of a Data Engineer & Course road-map (0) | 2021.08.24 |

